DP清理jumpout
版本DP11.30.13。本打算unidbg练手模拟调用mtgsig,结果失败了。只有静态分析有点儿学习成果。
jumpout分析
使用ida静态分析过程中遇到如下问题: 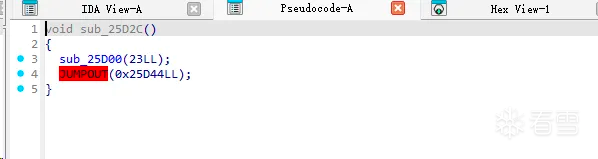
查看汇编信息,观察为什么导致这部分无法正常反汇编: 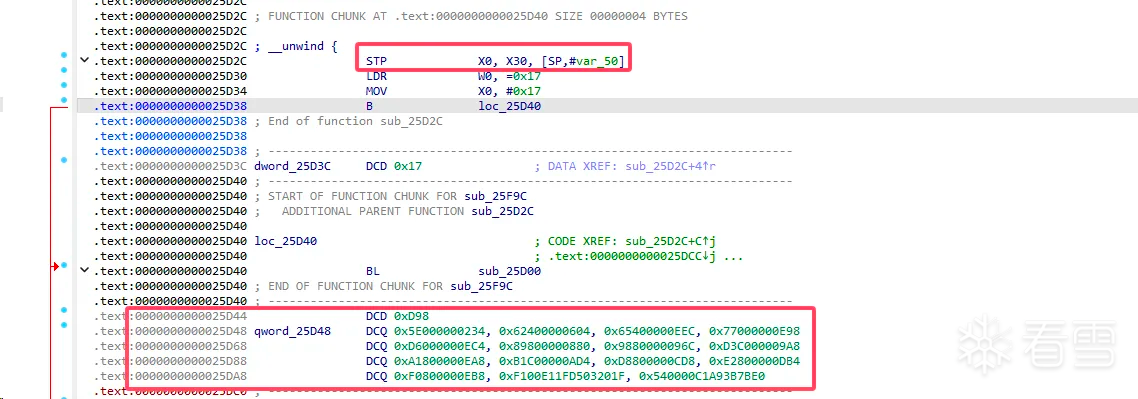
从上面可以看出jumpout位置是一些无法被识别的数据导致ida无法正常分析。从此函数函数开始分析,一开始保存X0和X30[LR]接着就是给X0赋值,接着跳转到另一个代码块,此代码块中只有一个函数调用sub_25D00。 sub_2D500函数比较简单只有几句话,首先是保存X0,X1寄存器的值,接着读取X30 + 4 * W0的值到W0,再给X30加上刚刚对去的值,最后恢复X0,X1的值。逻辑比较简单就是利用进入sub_25D00时链接寄存器的值为初始地址,再利用参数X0的值作为偏移读取本文件里的偏移量,通过修改LR链接寄存器的值完成间接跳转,正好导致ida无法正常分析。猜测之前jumpout的地址估计就是偏移表。X0`X30[LR]`sub_25D00
sub_2D500`X0,X1X30 + 4 * W0W0X30X0,X1sub_25D00X0`
简单验证
因为逻辑简单,涉及到的汇编语句也不多,简单的使用unicorn模拟执行验证上面的分析是否正确。
# unicorn虚拟机初始化
mu = Uc(UC_ARCH_ARM64, UC_MODE_ARM)
# 内存区域初始化
BASE_ADDR = 0x40000000
BASE_SIZE = 4 * 1024 * 1024 # 4MB
mu.mem_map(BASE_ADDR, BASE_SIZE)
# 堆栈初始化
STACK_ADDR = 0x10000000
STACK_SIZE = 0x00100000
mu.mem_map(STACK_ADDR, STACK_SIZE)
logger.debug(f"Memory map {hex(STACK_ADDR)} - {hex(STACK_ADDR + STACK_SIZE)}")
mu.reg_write(UC_ARM64_REG_SP, STACK_ADDR + STACK_SIZE)
# 模拟执行汇编指令
ks = Ks(KS_ARCH_ARM64, KS_MODE_LITTLE_ENDIAN)
assembly_code = ';'.join([
'STP X0, X30, [SP,#-0x50]',
'LDR W0, =2',
'STP X0, X1, [SP,#-0x10]!',
'LDR W0, [X30,W0,UXTW#2]',
'ADD X30, X30, W0,UXTW',
'LDP X0, X1, [SP],#0x10',
])
encoding, count = ks.asm(assembly_code.strip())
logger.debug(f"Assembly code {bytes(encoding).hex()}, bytes count {count}")
# 将代码写入内存
mu.mem_write(BASE_ADDR, bytes(encoding))
# hook 指令
def hook_code(uc: Uc, address: int, size: int, user_data):
# 尝试读取指令
inst = uc.mem_read(address, size)
# capstone 反汇编尝试
md = Cs(CS_ARCH_ARM64, CS_MODE_ARM)
for i in md.disasm(inst, address):
logger.debug(f">>> {hex(i.address)}:\t{i.mnemonic}\t{i.op_str}")
mu.hook_add(UC_HOOK_CODE, hook_code)
def hook_mem_read_unmapped(uc: Uc, access: int, address: int, size: int, value, user_data):
logger.debug(f">>> Tracing memory read at {hex(address)}, size: {hex(size)}")
mu.hook_add(UC_HOOK_MEM_READ_UNMAPPED, hook_mem_read_unmapped)
def hook_mem_read(uc: Uc, access: int, address: int, size: int, value, user_data):
data = uc.mem_read(address, size)
logger.debug(f">>> Tracing memory read at {hex(address)}, size: {hex(size)}, data: {data.hex()}")
mu.hook_add(UC_HOOK_MEM_READ, hook_mem_read)
mu.reg_write(UC_ARM64_REG_X30, 0x40000000)
# 启动
mu.emu_start(BASE_ADDR, BASE_ADDR + (4 * count)) # 这里只执行一句指令。
# 执行完之后,查看寄存器状态
sp_value = mu.reg_read(UC_ARM64_REG_SP)
logger.debug(f"After simulate sp value: {hex(sp_value)}")
logger.debug(f"After simulate X0 value: {hex(mu.reg_read(UC_ARM64_REG_X0))}")
logger.debug(f"After simulate X30 value: {hex(mu.reg_read(UC_ARM64_REG_X30))}")
如上图所示简单执行之后和之前分析的逻辑一致。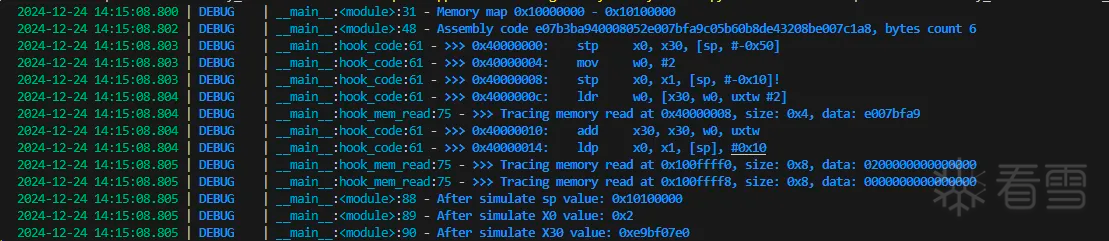
修复
修复逻辑也比较简单,就是手动计算真实跳转地址,修改进入sub_25D00跳转代码块之前的那个直接跳转地址即可。 sub_25D00
下面是ida修复代码:
import idc
import idautils
import ida_funcs
import ida_bytes
from keystone import Ks, KS_ARCH_ARM64, KS_MODE_LITTLE_ENDIAN
ks = Ks(KS_ARCH_ARM64, KS_MODE_LITTLE_ENDIAN)
# 1. 查找所有调用0x25d00修改LR函数的代码块。
def get_func_references(func_ea):
references = []
# 获取函数开始地址
func_st_ea = ida_funcs.get_func(func_ea).start_ea
print(f"目标函数起始地址: {hex(func_st_ea)}")
# 遍历所有的代码引用
for ref_ea in idautils.CodeRefsTo(func_st_ea, True):
references.append(ref_ea)
return references
# 2. 查找所有调用跳转0x25d00代码块的应用。
def get_block_references(block_ea):
return [ref_ea for ref_ea in idautils.CodeRefsTo(block_ea, True)]
# 3. 获取X0指令的立即数
def find_imm_offset(instruction: str):
temp = instruction.split()
opcode = temp[0]
# 暂时判定前一句都是mov给x0赋值
# 注意分割之后的注释。
if opcode.strip() == "MOV" and temp[1].strip().startswith('X0'):
return eval(temp[2].replace('#', ''))
if opcode.strip() == "LDR" and temp[1].strip().startswith("W0"):
return eval(temp[2].replace('=', ''))
else:
return -1
# 4. 计算并读取真实偏移表
def read_offset_table(lr_value, x0_value):
offset = lr_value + (4 * x0_value)
# print(hex(offset))
temp = ida_bytes.get_bytes(offset, 4)
value = int.from_bytes(temp, byteorder='little')
return value
# 5. patch替换无条件跳转
def patch_b_addr(current_addr, real_addr):
real_inst = f"B {hex(real_addr)}"
asm_list, _ = ks.asm(real_inst, addr=current_addr)
asm_bytes = bytes(asm_list)
print(f"real code: {asm_bytes.hex()}")
ida_bytes.patch_bytes(current_addr, asm_bytes)
func_ea = 0x25d00
func_refs = get_func_references(func_ea)
print("#" * 16)
for func_ref in func_refs:
lr_value = func_ref + 4 # 计算真实地址的
block_refs = get_block_references(func_ref)
for block_addr in block_refs:
prev_addr = idc.prev_head(block_addr)
prev_inst = idc.GetDisasm(prev_addr)
# print(f"lr {hex(lr_value)}, block addr: {hex(block_addr)}")
x0_value = find_imm_offset(prev_inst)
# print(f"x0_value: {hex(x0_value)}")
real_addr = read_offset_table(lr_value, x0_value) + lr_value
print(f"block addr: {hex(block_addr)}, real addr: {hex(real_addr)}")
patch_b_addr(block_addr, real_addr)
print("#" * 16)
使用上面脚本能全部清理。清理后结果: 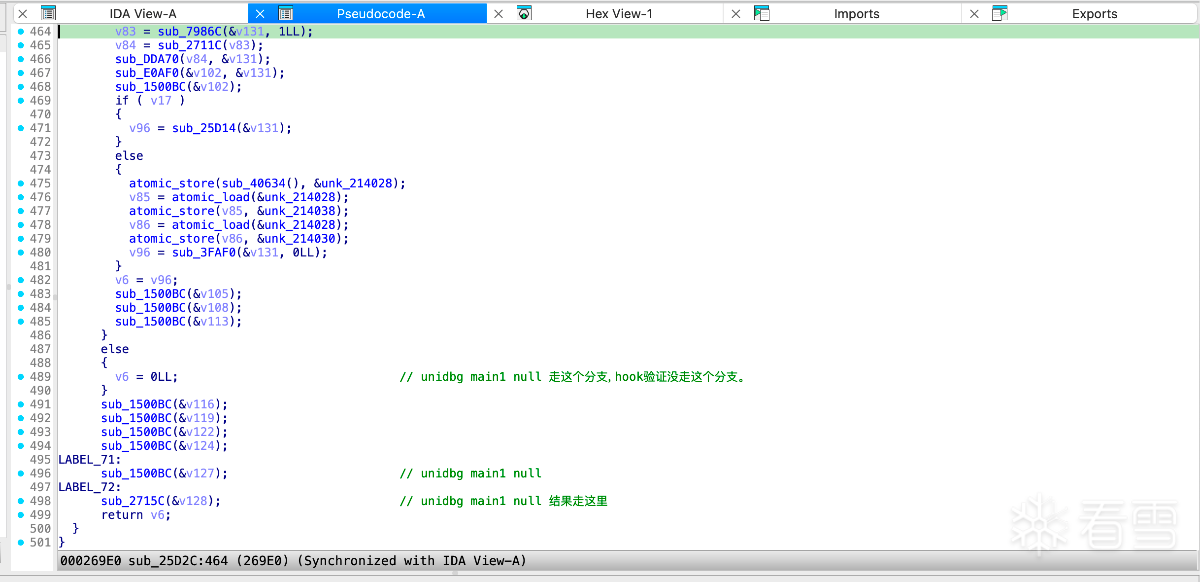
到此结束,这个so可以直接放到unidbg中模拟执行。但是我没有完成main(1)初始化,如果有大佬完成了给点提示。